RHEL Clustering
This is my comment + notes from Udemy Class
Starting/Stopping Cluster Services
Show Cluster Status
[root@nodea /] pcs cluster status
Cluster Status:
Stack: corosync
Current DC: nodea.example.com (version 1.1.19-8.e17-c3c624ea3d) - partition with quorum
Last updated : Fri Mar 15 14:08:01 2019
Last change: Fri MAr 15 14:06:39 2019 by hacluster via crmd on nodea.example.com
3 nodes configured
3 resources configured
PCSD Status:
nodea.example.com: Online
nodeb.example.com: Online
nodec.example.com: Onlien
stop cluster services from all nodes
[root@nodea /] pcs cluster stop -all
nodea.example.com: Stopping Cluster (pacemaker)...
nodeb.example.com: Stopping Cluster (pacemaker)...
nodec.example.com: Stopping Cluster (pacemaker)...
nodea.example.com: Stopping Cluster (corosync)...
nodeb.example.com: Stopping Cluster (corosync)...
nodec.example.com: Stopping Cluster (corosync)...
start cluster services from all nodes
[root@nodea /] pcs cluster start -all
nodea.example.com: Starting Cluster (pacemaker)...
nodeb.example.com: Starting Cluster (pacemaker)...
nodec.example.com: Starting Cluster (pacemaker)...
nodea.example.com: Starting Cluster (corosync)...
nodeb.example.com: Starting Cluster (corosync)...
nodec.example.com: Starting Cluster (corosync)...
stop cluster services from the specific node
[root@nodea /] pcs cluster stop nodeb.example.com
nodeb.example.com: Stopping Cluster (pacemaker)...
nodeb.example.com: Stopping Cluster (corosync)...
start cluster services from the specific node
[root@nodea /] pcs cluster stop nodeb.example.com
nodeb.example.com: Starting Cluster (pacemaker)...
nodeb.example.com: Starting Cluster (corosync)...
Enabling/Disabling Cluster Services
enable cluster services from all nodes
[root@nodea /] pcs cluster enable --all
nodea.example.com: Cluster Enabled
nodeb.example.com: Cluster Enabled
nodec.example.com: Cluster Enabled
disable cluster services from all nodes
[root@nodea /] pcs cluster disable --all
nodea.example.com: Cluster Disabled
nodeb.example.com: Cluster Disabled
nodec.example.com: Cluster Disabled
enable cluster services from the specific node
[root@nodea /] pcs cluster enable nodeb.example.com
nodeb.example.com: Cluster Enabled
disable cluster services from the specific node
[root@nodea /] pcs cluster disable nodeb.example.com
nodeb.example.com: Cluster Disabled
Standby/Unstandby Cluster Services
standby node
[root@nodea /] pcs cluster standby noded.example.com
[root@nodea /] pcs cluster status
Stack: corosync
Current DC: nodea.example.com (version 1.1.19-8.e17-c3c624ea3d) - partition with quorum
Last updated: Fri Mar 15 18:07:44 2019
Last change: Fri Mar 15 18:07:27 2019 by root via cibadmin on nodea.example.com
4 nodes configured
4 resources configured
Node noded.example.com: standby
Online: [ nodea.example.com nodeb.example.com nodec.example.com ]
Full list of resources:
fence_nodea (stonith:fence_xvm): Started nodea.example.com
fence_nodeb (stonith:fence_xvm): Started nodeb.example.com
fence_nodec (stonith:fence_xvm): Started nodec.example.com
fence_noded (stonith:fence_xvm): Started noded.example.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
unstandby node
[root@nodea /] pcs cluster unstandby noded.example.com
Adding/Removing a Cluster Node
add firewall rule for high-availability
[root@noded /] firewall-cmd --add-service=high-availability --permanent
success
start PCS service
[root@noded /] systemctl start pcsd
Enable the PCS service
[root@noded /] systemctl enable pcsd
Created symlink from /etc/systemd/system/multi-user.target.wants/pcsd.service to /usr/lib/systemd/system/pcsd.service.
Set the password for hacluster user (*this is only for testing)
[root@noded /] echo "redhat" | passwd ---stdin hacluster
Changling password for user hacluseter.
passwd: all authentication tokens updated successfully.
authenticate PCS cluster services from the existing node
[root@nodea /] pcs cluster auth -u hacluster noded.example.com -p redhat
Changling password for user hacluseter.
passwd: all authentication tokens updated successfully.
create node from the existing node
[root@nodea /] pcs cluster node add noded.example.com
Disabling SBD service...
noded.example.com: sbd disabled
Sending remote node configuration files to 'noded.exaple.com'
noded.example.com: successful distribution of the file 'pacemaker_remote authkey'
nodea.example.com: Corysync updated
nodeb.example.com: Corysync updated
nodec.example.com: Corysync updated
Setting up corosync...
noded.example.com: succeeded
Sychronizing pcsd cerfiicateds on nodes noded.example.com...
Remove node from the cluster
[root@nodea /] pcs cluster node remove noded.example.com
...
authenticate PCS cluster services from the new node
[root@noded /] pcs cluster auth -u hacluster -p redhat
nodea.example.com: Authorized
nodeb.example.com: Authorized
nodec.example.com: Authorized
noded.example.com: Authorized
enable and Start cluster services on the new node
[root@noded /] pcs cluster enable
[root@noded /] pcs cluster start
Starting Cluster (corosync)...
Starting Cluster (pacemaker)...
Fencing Configuration
install fence service
[root@service /] yum install fence-virt fence-vrtd fence-virtd-multicast fence-virtd-libvirt
...
Complete!
create a secret key for fencing
[root@service /] mkdir -p /etc/cluster
[root@service /] dd if=/dev/random of=/etc/cluster/fence_xvm.key bs=512 count=1
0+1 records in
0+1 records out
115 bytes (115 B) copied, 0.000302385 s, 380 kB/s
Configure Fence Daemon
[root@service /] fence_virtd -c
Module search path [/usr/lib64/fence-vrt]:
Listener module [multicast]:
Multicast IP Address [225.0.0.12]:
Using ipv4 as family.
Multicast IP Port [1229]:
Interface [virbr0]:
Key File [/etc/cluster/fence_xvm.key]:
Backend module [libvirt]:
...
=== End Configuration ===
Replace /etc/fence_virt.conf with the above [y/N]? y
restart the service
[root@service /] systemctl restart fence_vrtd
[root@service /] systemctl enable fence_vrtd
Add the Fence Service Port to firewall rule
[root@service /] firewall-cmd --add-port=1229/udp --permanent
success
[root@service /] firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: br0 ens33
sources:
services: ssh dhcpv6-client
ports: 1229/udp
protocols:
masquerade : no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
copy key file to all nodes
[root@service /] scp -p /etc/cluster/fence_xvm.key nodea:/etc/cluster/
[root@service /] scp -p /etc/cluster/fence_xvm.key nodeb:/etc/cluster/
[root@service /] scp -p /etc/cluster/fence_xvm.key nodec:/etc/cluster/
[root@service /] scp -p /etc/cluster/fence_xvm.key noded:/etc/cluster/
list all available fencing agents
[root@nodea /] pcs stonith list
...
fence_ilo4 - Fence agent for IPMI
...
fence_ilo_ssh - Fence agent for HP iLO over SSH
...
fence_vmware_rest - Fence agent for VMware REST API
fence_xvm - Fence agent for virtual machines
describe a specific fencing agent
[root@nodea /] pcs stonith describe fence_xvm
...
create stonith
[root@nodea /] pcs stonith create fence_nodea fence_xvm port="nodea.example.com" pcmk_host_list="nodea.example.com"
delete stonith
[root@nodea /] pcs stonith delete fence_noded
Attempting to stop: fence_noded... Stopped
show fencing agent configured
[root@nodea /] pcs stonith show
fence_nodea (stonith:fenc_xvm) : Started nodea.example.com
fence_nodeb (stonith:fenc_xvm) : Started nodeb.example.com
fence_nodec (stonith:fenc_xvm) : Started nodec.example.com
list fence nodes
[root@nodea /] fence_svm -o list
nodea.example.com b151fad6-5434-3446-fdh4-dfd3545cgffdg on
nodeb.example.com s3ks3f0d-3403-6344-fhd4-cgffdgdfd3545 on
nodec.example.com b151fad6-3035-3644-d4fh-dfd3cgffdgds2 on
noded.example.com ea343l42-2892-4634-8dh4-ah34545cgffdg on
show fence status
[root@nodea /] fence_xvm -H nodea.example.com -o status
Status: ON
power off node
[root@nodea /] fence_xvm -H nodea.example.com -o off
power on node
[root@nodea /] fence_xvm -H nodea.example.com -o on
Quorum Operations
show quorum status (quorate)
[root@nodea /] corosync-quorumtool
------------------
Date: Fri Mar 15 19:57:06 2019
Quorum provider: corosync_votequorum
Nodes: 4
Node ID: 1
Ring ID: 1/892
Quorate: Yes
Votequorum information
----------------------
Expected votes: 4
Highest expected: 4
Total votes: 4
Quorum: 3
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
1 1 nodea.example.com (local)
2 1 nodeb.example.com
3 1 nodec.example.com
4 1 noded.example.com
Show Quorum Status (Blocked)
[root@nodea /] corosync-quorumtool
------------------
Date: Fri Mar 15 19:57:06 2019
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 1
Ring ID: 1/908
Quorate: No
Votequorum information
----------------------
Expected votes: 4
Highest expected: 4
Total votes: 2
Quorum: 3 Activity blocked
Flags:
Membership information
----------------------
Nodeid Votes Name
1 1 nodea.example.com (local)
2 1 nodeb.example.com
Update Quorum to set wait for all
[root@nodea /] pcs quorum update wait_for_all=1
[root@nodea /] pcs quorum update auto_tie_breaker=1
Creating/Configuring Resources
Describe Resource Agent
[root@nodea /] pcs resource describe Filesystem
Create Resource and add to Resource Group
[root@nodea /] pcs resource create newfs Filesystem device=workstation.example.com:/exports/www directory=/mt1 fstype=nfs options=ro
Assumed agent name 'ocf:heartbeat:Filesystem' (deduced from 'Filesystem')
[root@nodea /]
[root@nodea /] pcs resource create webip IPaddr2 ip-192.168.209.150 nic=eth0:1 cidrr_netmask=24 --group mygroup
Assumed agent name 'ocf:heartbeat:IPaddr2' (deduced from 'IPaddr2')
[root@nodea /]
[root@nodea /] pcs resource create webserv apache --group mygroup
Assumed agent name 'ocf:heartbeat:apache' (deduced from 'apache')
Show Resource
[root@nodea /] pcs resource show
Resource: newfs (class=ocf provider=heartbeat type=Filesystem)
Attributes: device=workstation.example.com:/exports/www directory=/mnt1 fstype=nfs options=ro
Operations: mnonitor interval=20s timeout=40s (newfs-monitor-interval-20s)
notify interval=0s timeout=60s (newfs-notify-interval-0s)
start interval=0s timeout=60s (newfs-start-interval-0s)
stop interval=0s timeout=60s (newfs-stop-interval-0s)
Update Resource
[root@nodea /] pcs resource update newfs device=workstation
Delete Resource
[root@nodea /] pcs delete newfs
Disable Resource Group
[root@nodea /] pcs resource disable mygroup
Enable Resource Group
[root@nodea /] pcs resource enable mygroup
Move Resource Group
[root@nodea /] pcs resource move mygroup nodec.example.com
Ban Resource Group
[root@nodea /] pcs resource ban mygroup nodec.example.com
Warning: Creating location constraint cli-ban-mygroup-on-nodec.example.com with a score of -INFINITY for resource mygroup on node nodec.example.com.
This will prevent mygroup from running on nodec.example.com until the constraint is removed. This will be the case even if nodec.example.com is the last node in the cluster
[root@nodea /] pcs constraint list
Location Constraints:
Resource: mygroup
Enabled on: nodea.example.com (score:INFINITY) (role: Started)
Disabled on: nodec.example.com (score:-INFINITY) (role: Started)
Ordering Constraints:
Colocation Constraints:
Ticket Constraints:
Remove Ban Resource Group
[root@nodea /] pcs resource clear mygroup nodec.example.com
[root@nodea /] pcs constraint list
Location Constraints:
Resource: mygroup
Enabled on: nodea.example.com (score:INFINITY) (role: Started)
Ordering Constraints:
Colocation Constraints:
Ticket Constraints:
Configuration/Log File
Corosync Configuration File and Log Path
vi /etc/corosync/corosync.conf
...
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
}
It logs to corosync log file by default.
Pacemaker Configuration File and Log Path
vi /etc/sysconfig/pacemaker
...
# PCMK_logfile=/var/log/pacemaker.log
How to sync Corysync Config files
[root@nodea /] pcs cluster sync
How to sync Pacemaker Config files
[root@nodea /] scp /etc/sysconfig/pacemaker nodeb:/etc/sysconfig
[root@nodea /] scp /etc/sysconfig/pacemaker nodec:/etc/sysconfig
[root@nodea /] scp /etc/sysconfig/pacemaker noded:/etc/sysconfig
[root@nodea /] pcs cluster stop --all
[root@nodea /] pcs cluster start --all
Resource Failures and How To Debug
How to see failcount
[root@nodea /] pcs resource failcount show webserv
Failcounts for resource 'webserv'
nodea.example.com: INFINITY
nodeb.example.com: INFINITY
nodec.example.com: INFINITY
How to start resource with debug mode
[root@nodea /] pcs resource debug-start webserv --full | less
...
Complex Resource Group (nfs)
create nfs file system resource
[root@nodea /] pcs resource create nfsfs Filesystem device=/dev/sda1 directory=/nfsshare fstype=xfs --group nfs
install nfs utils
[root@nodea /] yum install nfs-utils
[root@nodea /] systemctl stop nfs-lock # Make sure nfs-lock stop
[root@nodea /] systemctl disable nfs-lock # Make sure nfs-lock is disabled
create nfs server resource
[root@nodea /] pcs resource create nfsd nfsserver nfs_shared_infodir=/nfsshare/nfsinfo --group nfs
create nfs export resource
[root@nodea /] pcs resource create nfsexp exportfs clientspec="*" options=rw,sync,no_root_squash directory=/nfsshare fsid=1 --group nfs
create nfs ip resource
[root@nodea /] pcs resource create nfsip ip=192.168.209.150 cidr_netmask=24 --group nfs
result of creating nfs resource group
[root@nodea /] pcs status
Cluster name: cluster0
Last updated: tue Apr 2 12:22:16 2019
Last chang: Tue Apr 2 12:22:14 2019
Stack: corosync
Current DC: nodea.example.com (1) - partition with quorum
Version: 1.1.12-a14efad
3 Nodes configured
6 Resources configured
Online: [ nodea.example.com nodeb.example.com nodec.example.com ]
Full list of resources:
fence_nodea (stonith:fence_xvm): Started nodea.example.com
fence_nodeb (stonith:fence_xvm): Started nodeb.example.com
fence_nodec (stonith:fence_xvm): Started nodec.example.com
Resource Group: nfs
nfsfs (ocf::hearbeat:Filesystem): Started nodea.example.com
nfsd (ocf::hearbeat:nfsserver): Started nodea.example.com
nfsfs (ocf::hearbeat:exportfs): Started nodea.example.com
nfsip (ocf::hearbeat:IPaddr2): Started nodea.example.com
PCSD Status:
nodea.example.com: Online
nodeb.example.com: Online
nodec.example.com: Online
noded.example.com: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Managing Constraints
- Constraints are rules that place restrictions on the order in which resources or resource groups may be started, or the nodes on which they may run. Constraints are important for managing complex resource groups or sets of resource groups, which depend upon one another or which may interfere with each other.
- There are three main types of constraints :
- Order constraints : Control the order in which resources or resource groups are started and stopped.
- Location constraints : Control the nodes on which resources or resource groups may run.
- Colocation constraints : Control where two resources or resource groups may run on the same node.
Add Order Constraints
[root@nodea /] pcs constraint order A then B
Add Location Constraints (prefers)
[root@nodea /] pcs constraint location webserv prefers nodea.example.com
[root@nodea /] pcs constraint list
Location Constraints:
Resource: webserv
Enabled on: nodea.example.com (score:INFINITY)
Ordering Constraints:
Colocation Constraints:
[root@nodea /]
[root@nodea /] pcs constraint location webserv prefers nodea.example.com=200
[root@nodea /] pcs constraint list
Location Constraints:
Resource: webserv
Enabled on: nodea.example.com (score:200)
Ordering Constraints:
Colocation Constraints:
add location constraints (avoids)
[root@nodea /] pcs constraint location webserv avoids nodec.example.com
[root@nodea /] pcs constraint list
Location Constraints:
Resource: webserv
Enabled on: nodea.example.com (score:200)
Disabled on: nodec.example.com (score:-INFINITY)
Ordering Constraints:
Colocation Constraints:
list all constraints
[root@nodea /] pcs constraint list --full
Location Constraints:
Ordering Constraints:
Colocation Constraints:
show allocation scores
[root@nodea /] crm_simulate -sL
...
Resouce Stickeness
- When resource prefered node is nodea, and resource is failed over to nodeb. Even after nodea is re-available by restoring the node, aovid the situation the resource is fail over back to nodea a by setting resource-stickiness higher then preferred node score.
[root@nodea /] pcs resource defaults
resource-stickiness: 0
[root@nodea /] pcs resource defaults resource-stickiness=500
resource-stickiness: 0
Colocation Constraints
- Colocatoin consraints specify that two resources must (or must not) run on the same node. To set a colocatoin constraint to keep two resources or resource groups together.
[root@nodea /] pcs constraint colocation add B with A
- A colocation constraint with a score of -INFINITY can also be set to force the two resources or resource groups to never run on the same node.
[root@nodea /] pcs constraint colocation add B with A -INFINITY
Two Node Cluster Issue
No Room for Node Failure
As the quorum should be 50% + 1 vote, There is no room for failure with two nodes cluster.
two_node option : If one of the nodes goes down, the rest will satisfy the quorum
[root@nodea /] pvi /etc/corosync/corosync.conf
...
quorum {
provider: corosync_votequorum
two_node: 1
}
Split Brain
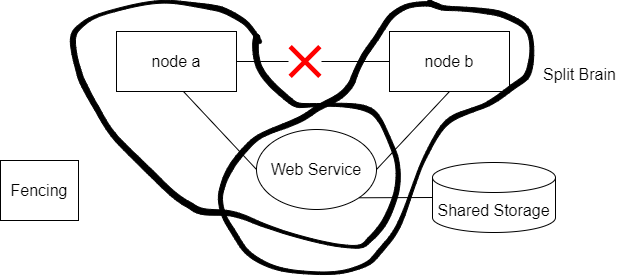 If node A and node B constitute a cluster but are unable to communicate with each other, then the following situations may arise:
If node A and node B constitute a cluster but are unable to communicate with each other, then the following situations may arise:
- Fencing is enabled (fence Racing): Each node will attempt to fence the other node, potentially leading to both nodes being fenced, thus isolating them from the cluster.
- Fencing is disabled : Each node will attempt to set up the cluster independently, possibly resulting in both nodes attempting to start resources simultaneously, leading to a corrupted status due to resource conflicts.
Fence Death/Fence Racing
To avoid the fence racing from the split brain situation, fence delay can be applied to one of the nodes, so when one node is fenced the other node will be delayed before fencing and start cluster.
Cluster does not start until both nodes have started
When two_node is enabled for two nodes cluster, wait-for-all option is also enabled. Because of this, the cluser may not start. So this option should be disabled to avoid the issue.
Configurating iSCSI Targets * Initiators
- Internet Small Computer System Interface (iSCSI) is an TCP/IP-based standard for connecting storage devices. iSCSI uses IP networks to encapsulate SCSI commands, allowing data to be transferred over long distances.
- iSCSI provides shared storage among a number of client systems. Storage devices are attached to servers (targets). Client systems (initiators) access the remote storage devices over IP networks.
- To the client systems, the storage devices appear to be locally attached. iSCSI uses the existing IP infrastructure and doe not require any additional cabling, as is the case with Fibre Channel (FC) storage area networks.
| Term | Description |
|---|---|
| initiator | An iSCSI client, typically available as software but also implemented as iSCSI HBAs. Initiators must be given unique names. |
| target | An iSCSI storage resource, configured for connection from an iSCSI server. Targets must be given unique names. A target provides one or more numbered block devices called logical units. An iSCSI server can provide many targets concurrently. |
| ACL | An Access Control List (entry), an access restriction using the node IQN (commonly the iSCSI initiator Name) to validate access permissions for an initiator. |
| discovery | Querying a target server to list configured targets. Target use requires an addtional access steps |
| IQN | An iSCSI Qualified Name, a worldwide unique name used to identify both initiators and targets, in the mandated naming format: iqn.YYYY-MM.com.reversed.domain[:optional_string] |
| iqn-Signifying that this name will use a domain as its identifier. | |
| YYYY-MM-The first month in which the domain name was owned. | |
| com.reversed.domain-The reversed domain name of the organization creating this iSCSI name. | |
| optional_string-An optional, colon-prefixed string assigned by the domain owner as desired while remaining worldwide unique. It may include colons to seperate organization boundaries. | |
| login | Authenticating to a target or LUN to begin client block device use. |
| LUN | A Logical Unit Number, numbered block devices attached to and available through a target. One or more LUNs may be attached to a single target, although typically a target provides only on LUN. |
| node | Any iSCSI intiator or iSCSI target, identified by its IQN. |
| portal | An IP address and port on a target or initiator used to establish connections. Some iSCSI implementations use portal and node interchangeably. |
| TPG | Target Portal Group, the set of interface IP addresses and TCP ports to which a specific iSCSI taret will listen. Target configuration (e.g., ACLs) can be added to the TPG to coordinate settings for multiple LUNs. |
Managing High Availability Logical Volumes
clustered LVM
- All volume groups and logical volumes on shared storage are available to all cluster nodes all of the time.
- Clustered LVM is a good choice when working with a shared file system, like GFS2.
- The active/active configuration of logical volumes in a cluster using clustered LVM is accomplished by using a daemon called clvmd to propagate metadata changes to all cluster nodes. The clvmd daemon manages clustered volume groups and communicates their metadata changes made on one cluster node to all the remaining nodes in the cluster.
- In order to prevent multiple nodes from changing LVM metadata simultaneously, clustered LVM uses Distributed Lock Manager (DLM) for lock management. The clvmd daemon and the DLM lock manager must be installed prior to configuring clustered LVM.
HA-LVM
- A volume group and its logical volumes can only be accessed by one node at a time.
- HA-LVM is a good choice when working with a more traditional file system like ext4 or XFS and restricted access to just one node at a time is desired to prevent file system and/or data corruption.
Sharing a disk(lun) to all clustered nodes using iSCSI Server
Show the disk to be shared
[root@server ~] fdisk -l
...
Disk /dev/sdc: 1073 MB, 1073741824 bytes, 2097152 sectors
Units = sectors of 1 * 512 = 512 bytes
SEctor size (logical/physical) : 512 bytes / 512 bytes
I/O size (minimum/optimal) : 512 bytes / 512 bytes
Disk label type: dos
Disk Identifier: 0xafe66b96
...
Target
[root@server ~] targetcli
targetcli shell version 2.1.fb46
Copyright 2011-2013 by Datera, Inc and others.
For help on commands, type 'help'.
/> pwd
/
/> ls
o- / ..................................................................... [...]
o- backstores .......................................................... [...]
| o- block .................................................[Storage Object: 0]
| o- fileio ................................................[Storage Object: 0]
| o- pscsi .................................................[Storage Object: 0]
| o- ramdisk ...............................................[Storage Object: 0]
o- iscsi ........................................................ [Targets: 0]
o- loopback ..................................................... [Targets: 0]
/> cd backstores/block
/backstores/block>
/backstores/block> create sharedlun0 /dev/sdc
Created block storage object sharedlun0 using /dev/sdc.
/backstores/block> cd /iscsi
/iscsi> ls
o- iscsi .......................................................... [Targets: 0]
/iscsi> create
Created target iqn.2003-01.org.linux-iscsi.server.x8664:sn.dbee0df4bdc5.
Created TPG 1.
Global pref auto_add_default_portal=true
Created default portal listening on all IPs (0.0.0.0), port 3260.
/iscsi>
/iscsi> ls
o- iscsi .......................................................... [Targets: 1]
o- iqn.2003-01.org.linux-iscsi.server.x8664:sn.dbee0df4bdc5 ........ [TPGs: 1]
o- tpg1 ............................................. [no-gen-acls, no-auth]
o- acls ........................................................ [ACLs: 0]
o- luns ........................................................ [LUNs: 0]
o- portals .................................................. [Portals: 1]
o- 0.0.0.0:3260 ................................................... [OK]
/iscsi>
/iscsi> cd iqn.2003-01.org.linux-iscsi.server.x8664:sn.dbee0df4bdc5/
/iscsi/iqn.20....dbee0df4bdc5> ls
o- iqn.2003-01.org.linux-iscsi.server.x8664:sn.dbee0df4bdc5 .......... [TPGs: 1]
o- tpg1 ............................................... [no-gen-acls, no-auth]
o- acls .......................................................... [ACLs: 0]
o- luns .......................................................... [LUNs: 0]
o- portals .................................................... [Portals: 1]
o- 0.0.0.0:3260 ..................................................... [OK]
/iscsi/iqn.20....dbee0df4bdc5> cd tpg1/
/iscsi/iqn.20....dbee0df4bdc5/tpg1> cd luns
/iscsi/iqn.20....dbee0df4bdc5/tpg1/luns> create /backstores/block/sharedlun0
Created LUN 0.
/iscsi/iqn.20....dbee0df4bdc5/tpg1/luns> cd ..
/iscsi/iqn.20....dbee0df4bdc5/tpg1/luns> cd acls
/iscsi/iqn.20....dbee0df4bdc5/tpg1/acls> create iqn.1994-05.com.redhat:78adad1b615a
Created Node ACL for iqn.1994-05.com.redhat:78adad1b615a
Created mapped LUN0.
/iscsi/iqn.20....dbee0df4bdc5/tpg1/acls> create iqn.1994-05.com.redhat:5df419c4cced
Created Node ACL for iqn.1994-05.com.redhat:5df419c4cced
Created mapped LUN0.
/iscsi/iqn.20....dbee0df4bdc5/tpg1/acls> create iqn.1994-05.com.redhat:e680f92e652c
Created Node ACL for iqn.1994-05.com.redhat:e680f92e652c
Created mapped LUN0.
/iscsi/iqn.20....dbee0df4bdc5/tpg1/acls> exit
Global pref auto_save_on_exit=true
Configuration saved to /etc/target/saveconfig.json
Get IQN for iSCSI initiator (Client)
[root@nodea ~] cd /etc/iscsi/
[root@nodea iscsi] ll
total 16
-rw-r--r--. 1 root root 50 Apr 1 19:13 initiatorname.iscsi
-rw-------. 1 root root 11700 Feb 3 2015 iscsid.conf
[root@nodea iscsi] cat initiatorname.iscsi
InitiatorName=iqn.1994-05.com.redhat:78adad1b615a
[root@nodea iscsi] ssh nodeb
Last login: Thu Apr 4 11:35:17 2019 from 192.168.209.1
[root@nodeb ~] cd /etc/iscsi/
[root@nodeb iscsi] cat initiatorname.iscsi
InitiatorName=iqn.1994-05.com.redhat:5df419c4cced
[root@nodea iscsi] ssh nodec
Last login: Thu Apr 4 11:35:17 2019 from 192.168.209.1
[root@nodec ~] cd /etc/iscsi/
[root@nodec iscsi] cat initiatorname.iscsi
InitiatorName=iqn.1994-05.com.redhat:e680f92e652c
Discovery and map iSCSI device on the client
[root@nodea iscsi] iscsiadm -m discovery -t sendtargets -p 192.168.209.132
192.168.209.132:3260,1 iqn.2003-01.org.linux-iscsi.server.x8664:sn.dbee0df4bdc5
[root@nodea iscsi] iscsiadm -m node -T iqn.2003-01.org.linux-iscsi.server.x8664:sn.dbee0df4bdc5 -l
[root@nodea iscsi] fdisk -l
...
Disk /dev/sda: 1073 MB, 1073741824 bytes, 2097152 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal) : 512 bytes / 4194304 bytes
Disk label type: dos
Disk identifier: 0xafe66b96
...
# Do the same for other nodes
Check SCSI ID
[root@nodea iscsi] /usr/lib/udev/scsi_id -g -u /dev/sda
36001405af949bccb7ad41acb39da3a5b
Create Resource for iSCSI HA-LVM
Volume Group
[root@nodea ~] vgs # Volume Group Information
VG #PV #LV #SN Attr VSize Vfree
clustervg 1 1 0 wz--n- 1016.00m 516.00m
rhel 1 2 0 wz--n- 14.51g 40.00m
[root@nodea ~] lvs # Logical Volume Information
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy% Sync Convert
clusterlv clustervg -wi------- 500.00m
root rhel -wi-ao---- 12.97g
swap rhel -wi-ao---- 1.50g
[root@nodea ~]
[root@nodea ~] pcs resource create halvm LVM volgrpname=clustervg exclusive=true --group halvmgrp
[root@nodea ~] pcs status
...
Online: [ nodea.example.com nodeb.example.com nodec.example.com ]
Full list of resources:
fence_nodea (stonith:fence_xvm) : Started nodea.example.com
fence_nodeb (stonith:fence_xvm) : Started nodeb.example.com
fence_nodec (stonith:fence_xvm) : Started nodec.example.com
Resource Group: halvmgrp
halvm (ocf::heartbeat:LVM) : Started nodea.example.com
[root@nodea ~] lvs # Logical Volume Information
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy% Sync Convert
clusterlv clustervg -wi-a----- 500.00m
root rhel -wi-ao---- 12.97g
swap rhel -wi-ao---- 1.50g
[root@nodea ~]
[root@nodea ~] pcs resource create xfsfs Filesystem device="/dev/clustervg/clusterlv" directory="/mnt1" fstype="xfs" --group halvmgrp
[root@nodea ~] df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/mapper/clustervg-clusterlv 497M 26M 472M 6% /mnt1
...